공부를 하는 입장이기 때문에, 내용에 오류가 있을 수 있습니다. 오류가 있다면 적극적으로 알려주시면 감사합니다!
1. 데이터 삭제
데이터를 삭제하기 위해서는 먼저 데이터에 접근을 해야 한다. 모든 데이터를 접근하기 위해서는 DataFrame ['열 이름']로 접근하지만, 인덱싱을 하기 위해서는 다양한 함수를 사용해야 한다. 특정 부분만 확인하기 위해서는 loc [] 함수와 iloc [] 함수를 많이 사용한다.(둘 다 함수지만, '[ ]'를 사용한다.) loc ['행 이름', '열이름'] 함수의 경우는 레이블을 지정하면서 인덱싱을 할 수 있고, iloc [0,1] 함수는 정수를 지정(위치)해 인덱싱을 할 수 있다.
DataFrame.drop() 함수는 데이터 프레임에서 열을 삭제하는 함수이다. axis라는 매개변수를 이용해 index 열을 지울지, column 열을 지울지 선택할 수 있다.
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)은 NaN 값(결측값)이 있는 열을 삭제하는 함수이다. how라는 매개변수를 이용해 how가 any이면 열에 한 개라도 NaN값이 있으면 삭제가 되고, how가 all이면 열의 모든 값이 NaN이면 삭제한다.
데이터 정제(Data Cleaning)에는 필요한 열을 삭제하는 것도 있지만, 데이터가 중복되는 값이 있다면 이를 확인하고 알맞은 추가적인 작업을 진행해야 한다. 예를 들어, 우리가 사용하고 있는 도서 대출 데이터의 경우 같은 책 데이터가 여러개로 들어가있는 경우가 있다.
DataFrame.duplicated(subset=None, keep='first')은 중복되는 행을 확인하는 함수이다. keep 매개 변수를 사용해 중복된 값 중 어떤 값을 False로 처리할지 결정한다. 매개 변수로 first를 사용할 경우 처음 발견된 중복값은 False, 이후 중복된 값들은 True를 반환하고, last를 사용할 경우 마지막에 발견된 값만 True로 사용한다. keep = False를 사용할 경우 모든 중복된 값을 True로 반환한다.
이를 우리 데이터에서 확인하면 다음과 같다.
print(sum(ns_book.duplicated()))
print('')
print(ns_book.duplicated())
결과 값을 확인하면, 중복된 값이 0으로 나온다. 이는 duplicated() 함수가 기본적으로 데이터프레임에 있는 모든 열을 기준으로 중복된 행을 찾는다. 따라서 각각의 번호가 있는 이 데이터는 중복이 0으로 나온다.
특정 columns으로 중복된 행을 찾을 수 있다.

중복된 데이터들만 확인하면 다음과 같다.
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN'], keep=False)
ns_book3 = ns_book[dup_rows]
ns_book3.head()
우리가 사용한 데이터의 경우 중복된 이유가 여러가지 이지만, 같은 책이 여러권 있기 때문인 경우도 있다. 이 경우 각각의 대출 건수를 따로 적어놨기 때문에 데이터를 삭제 할때, 그냥 삭제하게 된다면 데이터의 오류가 있게 된다. 이 경우는 대출 권수를 합친 뒤 한개만 남겨놔야한다. 이럴 때, 합칠 데이터를 그룹으로 묶어서 계산을 하게 된다면, 계산이 편해진다.
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True) groupby()함수는 데이터 프레임의 특정열을 기준으로 데이터를 그룹화하여 연산을 도와주는 함수이다. groupby() 함수는 데이터를 DataFrameGroupBy 객체로 변환하여 그룹별 요약 통계나 집계를 쉽게 계산할 수 있다. 예를 들어, 중복된 값을 그룹화하여 각 그룹별 평균, 합계 등을 계산하거나, 필요한 데이터를 선택적으로 처리할 수 있다.
우리가 사용할 columns은 '도서명', '저자', 'ISBN', '권', '대출건수'를 사용할 것이다. 만약 같은 책의 경우 '도서명', '저자', 'ISBN', '권',는 같을 것이다. 따라서 '도서명', '저자', 'ISBN', '권'을 그룹의 기준으로 정하면 기준이 같은 경우 같은 그룹으로 묶이게 된다.
# 필요한 데이터 열만 사용
count_df = ns_book[['도서명','저자','ISBN','권','대출건수']]
# NaN 행 삭제 안하기, 추가 메소드가 없다면 DataFrameGroupBy 오브젝트가 생성이 됩다.
group_df = count_df.groupby(by=['도서명','저자','ISBN','권'], dropna=False)
group_df.head()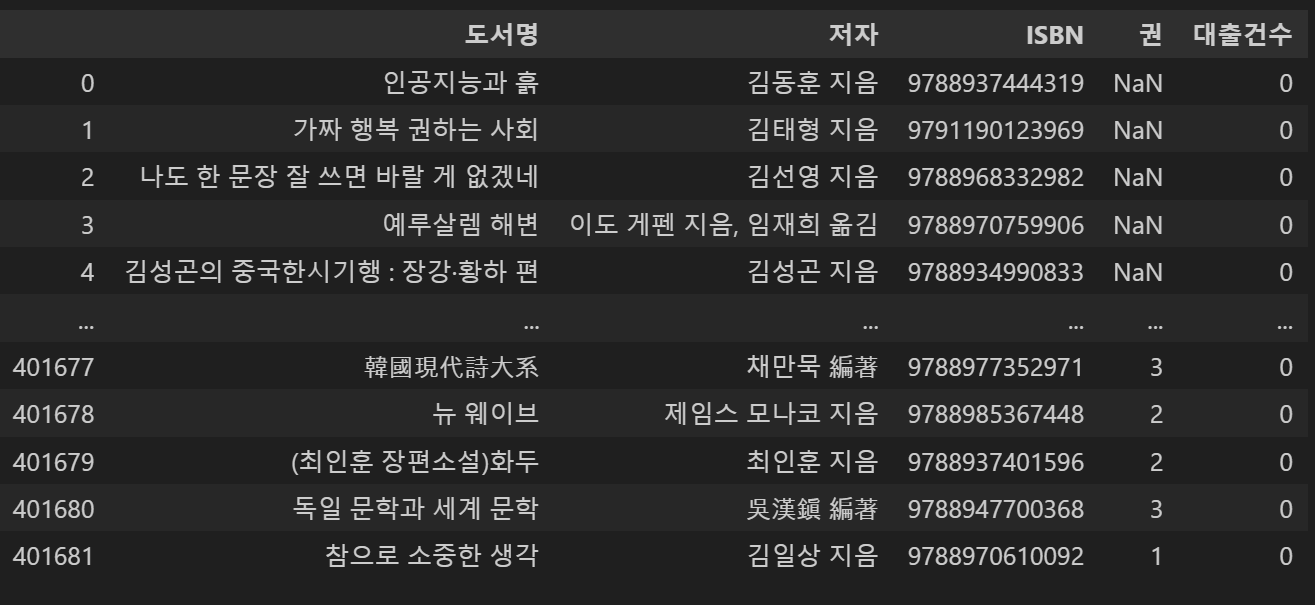
결과 값을 봐도 이해가 잘 되지 않아, 더 작은 분류로 확인하기 위해 '김상현'이라는 저자가 작성한 책만 뽑아 합쳐 보았다. 이 데이터들도 그룹으로 묶여 있기 때문에, sum() 함수를 사용하면 그룹 간의 데이터들이 합산된 결과를 확인할 수 있다. 특히 이 데이터프레임의 경우 5개의 열 중 4개를 기준으로 그룹화했으므로, 합산 가능한 열은 '대출 건수'뿐이다. 따라서 sum()을 적용하면 각 그룹별로 대출 건수 데이터가 합쳐진다.
test_df = count_df.loc[ns_df['저자']=='김상현 지음']
test_loan_count = test_group_df.sum()
test_loan_count

사진을 통해 알 수 있는 점은 도서명, 저자, ISBN, 권 수가 모두 같아야 하나의 그룹으로 묶인다는 것이다. 이 중 하나라도 다르면 다른 그룹으로 분류된다. 예를 들어, "나라서 행복해(인문 1, 독치 1)"라는 책은 도서명, 저자, ISBN, 권 수가 모두 동일하기 때문에 하나의 그룹으로 묶였고, sum()을 적용했을 때 대출 건수가 합쳐져 7권으로 계산된 것을 확인할 수 있다. 반면, "영어로 논문 쓰기=(The) Essential Guide to Writing English Papers"는 같은 책으로 보이지만, 제목의 'e' 대문자 차이 때문에 서로 다른 그룹으로 분류된 것을 볼 수 있다. 또한, 그룹화를 적용한 후 데이터프레임의 index는 그룹화 기준이 된 열 데이터로, 나머지 열은 columns로 표시된다는 점을 확인할 수 있다.
이런식으로 중복된 값을 처리해서 하나의 값으로 만든 데이터를 원본데이터에 반영해야 한다.
DataFrame.update(other, join='left', overwrite=True, filter_func=None, errors='ignore')은 DataFrame의 열은 객체의 동일한 열의 값으로 덮어씌우는 함수이다.
원래 데이터는 중복된 데이터가 아직 존재한다. 따라서 중복된 데이터를 하나로 줄인다. 그 후 update() 함수를 통하여 대출건수를 업데이트하면 중복된 데이터에 관해 데이터를 정제할 수 있다.
# 중복되는 것을 한개만 남기기
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN','권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()
# set_index메서드는 기존의 열을 인덱스로 설정하는 메서드.
ns_book3.set_index(['도서명','저자','ISBN','권'], inplace=True)
ns_book3.update(loan_count)
ns_book3[ns_book3.index.get_level_values('ISBN') == '9788965707172']
데이터를 업데이트를 할 때 index와 column이 같은 부분만 업데이트되기 때문에 원본 데이터를 업데이트할 데이터에 맞춰서 바꾼 후 업데이트를 진행하였다. 결과 값을 보면 원본데이터에 제대로 업데이트가 된 것을 알 수 있다.

DataFrame.set_index()함수를 통해 인덱스를 설정헀다면, DataFrame.reset_index()를 통하여 인덱스를 원래대로 돌려놓을 수 있다.
마지막으로 데이터의 열의 순서가 데이터를 다루면서 섞이게 됐는데, 이를 다시 정상적으로 바꾸고 저장한다.

# 열을 다시 정상적으로 바꾸고 저장
ns_book4 = ns_book4[ns_book.columns]
print(ns_book4.columns)
ns_book4.to_csv('../data/ns_book4.csv', index=False)
2. 데이터 수정
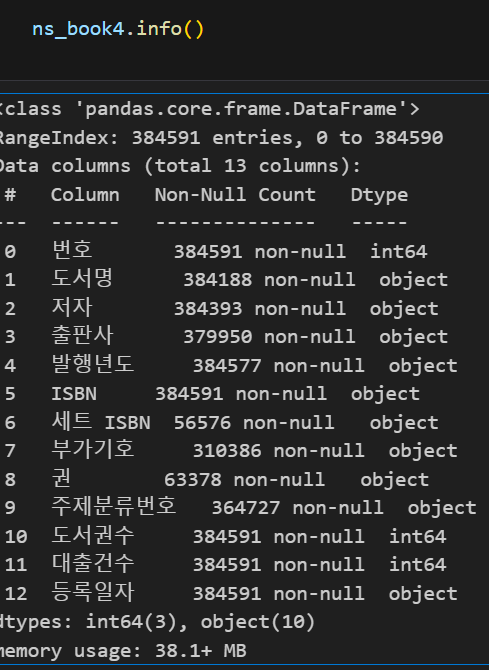
목표는 책의 정보 중 가장 중요한 도서명, 저자, 추판사, 발행 연도가 잘못되었다면 고치는 것이 목표이다. 먼저 데이터의 누락된 정보(결측값)가 있는지 확인해야 하는데, DataFrame.info()를 이용하거나 DataFrame.insna() 함수를 이용하면 결측값을 알 수 있다. insna() 함수의 경우 각 데이터가 비어있는지 boolean list로 반환해 주는 함수이다.

DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)는 결측값을 원하는 값으로 변경하는 함수이다.
DataFrame.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')는 객체 내 값을 다른 값으로 변경하는 함수이다.
이 두 함수로 데이터를 변경할 수 있다. replace함수의 regex는 정규식을 사용할지 정하는 매개변수이다.
08-2 정규 표현식 시작하기
정규 표현식에서는 메타 문자(meta characters)를 사용한다. 먼저 메타 문자가 무엇인지 알아보자. [TOC] ## 정규 표현식의 기초, 메타 문자 메타 문자란 원…
wikidocs.net
정규식은 생각보다 많이 사용하고 있다. 엑셀 같은 곳에서도 사용하고 나 같은 경우는 vscode 설정파일이나, gitignore 파일 등 많은 곳에 사용한다. 간단히 말하면 문자열에서 특정 패턴을 찾거나 검사해서 처리하는 도구이다.
자주 사용하는 문자 클래스는 다음과 같다.(점프 투 파이썬)
- \d - 숫자와 매치된다. [0-9]와 동일한 표현식이다.
- \D - 숫자가 아닌 것과 매치된다. [^0-9]와 동일한 표현식이다.
- \s - 화이트스페이스(whitespace) 문자와 매치된다. [ \t\n\r\f\v]와 동일한 표현식이다. 맨 앞의 빈칸은 공백 문자(space)를 의미한다.
- \S - 화이트스페이스 문자가 아닌 것과 매치된다. [^ \t\n\r\f\v]와 동일한 표현식이다.
- \w - 문자+숫자(alphanumeric)와 매치된다. [a-zA-Z0-9_]와 동일한 표현식이다.
- \W - 문자+숫자(alphanumeric)가 아닌 문자와 매치된다. [^a-zA-Z0-9_]와 동일한 표현식이다.
추가로 '. '은 아무런 문자를 표현하는 것이고, '* '반복을 의미한다. 또한 정규식에도 그룹을 만들어서 사용할 수 있다. '( )'를 사용해 그룹을 만들고 \1, \2를 통해 그룹을 나타낼 수 있다.
예를 들어, 발행 연도가 "20xx" 형식으로 기록된 데이터를 "xx 년"으로 바꾼다고 가정해보자. 여기서 "20xx"는 4자리 숫자이므로 정규 표현식으로 \d\d\d\d로 나타낼 수 있다. 필요한 부분인 "xx"를 그룹으로 지정하려면 \d\d(\d\d)를 사용하고, 그룹으로 선택한 값은 \1로 참조할 수 있다.
이를 pandas에서 replace()로 처리하면 다음과 같다.
ns_book4.replace({'발행년도': { r'\d\d(\d\d)': r'\1'}}, regex=True)[100:102]
이런 식으로 정규식을 사용해 잘못된 데이터를 바꾸고, 결측값을 저번처럼 web scraping을 통해 채웠다. 이는 새로운 내용이 없다고 생각해서 정리하지는 않겠다.
코드는 아래에서 볼 수 있다.(내가 책을 보면서 직접 타이핑한 코드)
Study_with_book/hongong_data_with_python/chap3 at main · dy0221/Study_with_book
Contribute to dy0221/Study_with_book development by creating an account on GitHub.
github.com
hongong_data_with_python/chap3/fixing_data.py
import sys, os
# 현재 파일의 부모 디렉터리를 sys.path에 추가하여 상위 폴더의 파일들을 가져올 수 있도록 설정
sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__))))
import pandas as pd
from bs4 import BeautifulSoup
import requests
import re
def get_book_info(row):
title = row['도서명']
author = row['저자']
pub = row['출판사']
year = row['발행년도']
isbn = row['ISBN']
# isbn으로 검색
url = 'https://www.yes24.com/Product/Search?domain=ALL&query={}'
response_isbn_web = requests.get(url.format(isbn))
soup_isbn_web = BeautifulSoup(response_isbn_web.text, 'html.parser')
# 도서 제목 구하기
try:
# 제목이 NaN이라면
if pd.isna(title):
title = soup_isbn_web.find('a', attrs={'class':'gd_name'}).get_text()
except AttributeError:
pass
# 저자 구하기
try:
# 저자가 NaN이라면
if pd.isna(author):
# 저자가 여러명 일 수 있음
authors = soup_isbn_web.find('span', attrs={'class':'info_auth'}).find_all('a')
author_list = [author.get_text() for author in authors]
author = ','.join(author_list)
except AttributeError:
pass
# 출판사 구하기
try:
if pd.isna(pub):
pub = soup_isbn_web.find('span', attrs={'class':'info_pub'}).find('a').get_text()
except AttributeError:
pass
# 출판 년도 구하기
try:
if year==-1:
year_str = soup_isbn_web.find('span', attrs={'class':'info_date'}).get_text()
year = re.findall(r'\d{4}', year_str)[0]
except AttributeError:
pass
return title, author, pub, year
if __name__=="__main__":
ns_book5 = pd.read_csv('data\\ns_book5.csv')
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() \
| ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
print('=========업데이트전================')
print(ns_book5.loc[na_rows,['도서명','저자','출판사','발행년도']])
updated_sample = ns_book5[na_rows].head(2).apply(get_book_info, axis=1, result_type='expand')
updated_sample.columns = ['도서명', '저자', '출판사', '발행년도']
print('=========업데이트후================')
print(updated_sample)
# 발행년도
# print('=========업데이트전================')
# print(ns_book5.loc[[61149,70566],['도서명','저자','출판사','발행년도']])
# updated_sample = ns_book5.loc[[61149, 70566], :].apply(get_book_info, axis=1, result_type='expand')
# # 열 이름을 원래 데이터프레임의 형식에 맞게 설정
# updated_sample.columns = ['도서명', '저자', '출판사', '발행년도']
# print('=========업데이트후================')
# print(updated_sample)
결과 값을 보면 출판사가 제대로 바뀐 것을 알 수 있다.

발행년도로 확인해도 -1에서 제대로 바뀐 것을 알 수 있다.

3. 숙제

참고 자료
[Python 완전정복 시리즈] 2편 : Pandas DataFrame 완전정복
안녕하세요! 파이썬 완전정복 시리즈의 저자 김태준 입니다. 파이썬 완전 정복 시리즈의 궁극적인 목표는 "자신만의 알고리즘 트레이딩 프로그램 만들기" 입니다. 본 도서는 독자…
wikidocs.net
pandas.Series.str.contains — pandas 2.2.3 documentation
Fill value for missing values. The default depends on dtype of the array. For object-dtype, numpy.nan is used. For StringDtype, pandas.NA is used.
pandas.pydata.org
08-2 정규 표현식 시작하기
정규 표현식에서는 메타 문자(meta characters)를 사용한다. 먼저 메타 문자가 무엇인지 알아보자. [TOC] ## 정규 표현식의 기초, 메타 문자 메타 문자란 원…
wikidocs.net
'혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공 분석] 다양한 그래프 그리기 (0) | 2025.02.23 |
|---|---|
| [혼공 분석] 선, 바 그래프 그리기 (0) | 2025.02.16 |
| [혼공 분석] 데이터 분석 (3) | 2025.02.03 |
| [혼공 분석] API, web scraping (4) | 2025.01.14 |
| [혼공 분석] 혼자 공부하는 데이터 분석 with 파이썬 (0) | 2025.01.05 |



