공부를 하는 입장이기 때문에, 내용에 오류가 있을 수 있습니다. 오류가 있다면 적극적으로 알려주시면 감사합니다!
1. API
API(Application Programming Interface)란 서로 다른 소프트웨어 사이에서 데이터를 주고받거나 기능을 호출할 수 있도록 돕는 인터페이스를 의미한다. 예를 들어, A라는 프로그램이 a'라는 정보를 B라는 프로그램에 전달하려고 할 때, B는 A가 내부적으로 어떤 방식으로 a'를 구했는지 알 필요가 없다. A와 B는 a'의 형식과 전달 방법에 대해서만 사전에 약속하고 이를 따라 사용하면 된다.
이처럼 두 소프트웨어(시스템) 사이에 정보의 형식과 교환 방식을 정의하고 규칙을 정리한 것을 API라고 한다. 대표적으로 이에 사용하는 방법으로 JSON(JavaScript Object Notation)과 XML(eXtebsubke Markup Language)가 있다.
2. JSON
JSON은 파이썬에서 딕셔너리와 굉장히 비슷하다. key와 value를 중괄호를 통해 정의하는 방식으로 이루어진다. 하지만 중요한 점은 키와 값을 큰따옴표에 감싸주어야 한다.
# "" 반드시 큰따옴표 사용해야한다.
{"name": "혼자 공부하는 데이터 분석"}
파이썬에서 JSON을 다룰 때는 비슷한 것뿐만 아니라, 딕셔너리로 바꿔 사용할 수 있어 편리하다. 다만 딕셔너리는 파이썬 객체이므로 웹 기반 API로 데이터를 주는 경우 문자열(str)로 바꾸어서 전달해야 한다. 그리고 이를 도와주는 파이썬 라이브러리는 json이 있다.
json.dumps(), json.loads() 함수는 JSON객체를 딕셔너리로, 딕셔너리를 JSON 문자열로 바꿔주는 함수이다.
d = {"name": "혼자 공부하는 데이터 분석"}
# dict를 json으로 쓰기 위해 str로 바꿈
d_str = json.dumps(d, ensure_ascii=False)
print(type(d_str))
# str을 다시 파이썬 객체로(딕셔너리)
d2 = json.loads(d_str)
print(type(d2))
JSON객체를 여러 개 담고 싶을 때는, list를 사용하는 것처럼 사용하면 된다.
# json객체를 여러개를 다루는 방식은 파이썬 리스트와 비슷하다.
d4_str = \
[
{"name": "혼자 공부하는 데이터 분석", "author": "박해선", "year": 2022},
{"name": "혼자 공부하는 머신러닝+딥러닝", "author": "박해선", "year": 2020}
]
import pandas as pd
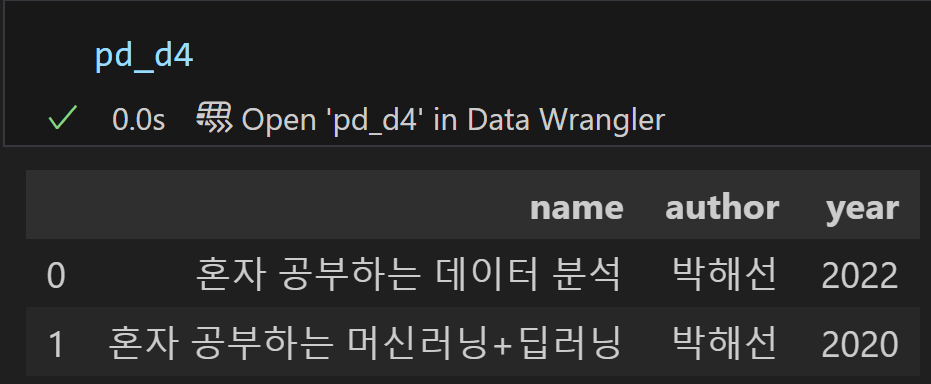
d4 = json.dumps(d4_str)
pd_d4 = pd.read_json(d4)
JSON으로 바꾸고, 판다스의 read_json함수로 데이터 프레임을 만들어도 잘 작동하는 것을 확인할 수 있다.

3. XML
xml은 html와 비슷하게 <element> data </element> 형식으로 데이터를 계층 구조로 저장한다. 파이썬에서 JSON은 str객체를 딕셔너리로 변환해 사용했다면, XML은 Element 클래스의 객체로 변환해서 사용해야 한다. 이는 xml.etree.ElementTree라는 라이브러리에서 fromstring() 함수를 이용하여 사용할 수 있다.
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
"""
# xml은 Element 클래스의 객체로 바꿔주어야 한다.
import xml.etree.ElementTree as et
book = et.fromstring(x_str)
print(type(book))
print(book)
XML 객체를 여러 개를 저장하고 싶다면, 부모 엘리먼트를 추가하여 저장할 수 있다.
x2_str = """
<books>
<book>
<name>혼자 공부하는 데이터 분석</name>
<author>박해선</author>
<year>2022</year>
</book>
<book>
<name>혼자 공부하는 머신러닝+딥러닝</name>
<author>박해선</author>
<year>2020</year>
</book>
</books>
"""
books = et.fromstring(x2_str)
XML은 엘리먼트의 이름인 tag, 데이터인 text, 속성 attribute로 구성된다.
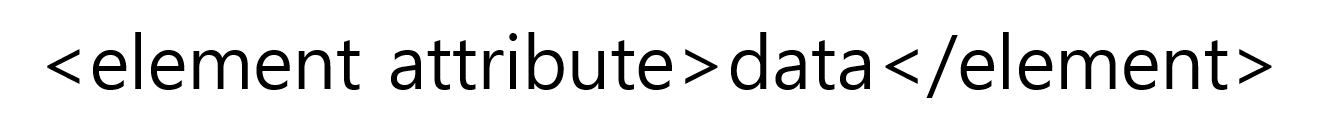
위에 x_str에서 tag는 최상위 엘리먼트인 <book>에 해당한다.

엘리먼트의 데이터(text)를 얻고 싶다면, XML.findtext() 함수를 이용해서 얻을 수 있다. 인자로 element의 tag를 넣어 구할 수 있다.
# xml 요소로 변환
book = et.fromstring(x_str)
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
name, author, year
만약 x2_str처럼 엘리먼트의 tag가 같은 경우가 있을 수 있다. 이때는 모든 엘리먼트를 반환해 주는 XML.findall() 함수와 반복문을 이용하면 모든 데이터를 얻을 수 있다.
# xml 요소로 변환
books = et.fromstring(x2_str)
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name, author, year)
findtext()나 findall() 함수의 경우 주의할 점이 있다. 바로 자식 엘리먼트들 까지만 찾는다는 것이다. 만약 구하고자 하는 엘리먼트가 자식의 자식이거나 그 아래인 경우 이 함수들을 사용할 수 없다.(적절히 사용해 접근해야 한다.)
4. Web api사용해 보기
일반적으로 공공기관들의 데이터들은 web api로 접근할 수 있다. 책에서 사용하는 도서관 정보 나루의 데이터 또한 web api방식으로 작동한다. 보통 사이트에 들어가면 어떤 방식으로 데이터를 가져올 수 있는지 확인할 수 있는데, 개인마다 key를 발급받고, 특정 url에 사이트에서 하라는 데로 key를 합쳐 들어가면, 해당 키가 데이터에 접근이 가능하면 data를 볼 수 있는 방식으로 작동한다.
이번에 할 것은 20대 인기 도서들의 쪽수를 구하는 것이다. 쪽수를 구하기 위해 인기 도서들이 무엇인지 알아야한다. 이는 도서관 정보나루에 api로 제공하고 있다. 도서관 정보나루에 직접 가보면 데이터를 어떤 식으로 받을 수 있을지 자세히 나와 있다. 원하는 데이터를 고르게 되면 아래에 url이 생성이 되는데 아래 url에 나의 인증키만 적용하면 된다.
인기대출도서 - 데이터 제공 - 도서관 정보나루
인기대출도서 전국 공공도서관에서 많이 대출된 도서를 보실 수 있습니다. 데이터 제공 인기대출도서 검색 조건들을 선택한 후 데이터를 다운로드 하거나, API 이용신청을 할 수 있습니다. 활용
www.data4library.kr

url의 데이터를 파이썬에서 받아오려면, requests 라이브러리를 사용해야 한다. request.get() 함수를 사용하여 데이터를 받을 수 있다. 나의 키만 따로 auth_key.py에 저장해서 불러와서 사용했다.
import requests
from auth_key import auth_key
url = "http://data4library.kr/api/loanItemSrch?&startDt=2021-04-01&endDt=2021-04-30&age=20authKey="
juso = url + auth_key
response = requests.get(juso)
# 200: 요청 성공 (파일 다운로드 가능).
# 404: 요청한 파일이 존재하지 않음 (Not Found).
# 500: 서버 에러 (Server Error).
print(response.status_code)
if response.status_code == 200:
try:
data = response.json()
print(data)
except ValueError as e:
print(e)
# UTF-8으로 인코딩된 문자열을 받을 수 있다.
print(response.text)
else:
print(f"Failed to get data. Status code: {response.status_code}")
데이터 접근이 가능하면 데이터를 받을 수 있다고 했는데, 이를 하기 위해서는 도서관 정보나루에서 데이터 신청을 해야 한다. 나는 데이터 신청을 하지 않았기 때문에, 데이터 접근이 불가능하고 그에 따라 위와 같은 결과가 나왔다.
request.get()로 받은 객체(response)는 원본 텍스트를 담고 있는 response.text를 통하여 접근이 가능하고, response.json()으로 JSON으로 받을 수 있다. 또한 response.status_code를 통해 해당 HTTP의 상태를 확인할 수 있다.
데이터를 신청하고 허락 받는데 시간이 걸리기 때문에 데이터 신청을 하지는 않았고, 웹사이트의 왼쪽 아래를 보면 CSV파일을 받을 수 있다. 나는 이걸 이용해서 data를 받아왔다. Web api로 받았을 경우 조금은 다르겠지만 이것도 적당히 슬라이싱을 하면 데이터 프레임으로 만들 수 있다.
도서관 정보나루에서 위의 설정으로 데이터를 받아서 보게 되면, 다음과 같은 내용이 위에 추가되어 있다.
검색조건
대출기간,2021-04-01 ~ 2021-04-30
성별,전체
연령,20대
지역,전체
ISBN 부가기호,전체
주제,전체
제공기관 : 국립중앙도서관
데이터 제공일 : 2025-01-13
이용허락조건 : 저작자표시(BY) - 저작자와 출처 등을 표시하면 영리 목적의 이용이나 변경 및 2차적 저작물의 작성을 포함한 자유이용을 허락합니다.
다음 부분을 지우면 우리가 아는 CSV파일 형식이므로 csv파일로써 사용할 수 있다.
CSV파일을 보면 마지막에 ', '가 있어 데이터 프레임으로 불러오면 None값을 가진 열이 마지막에 추가된다.
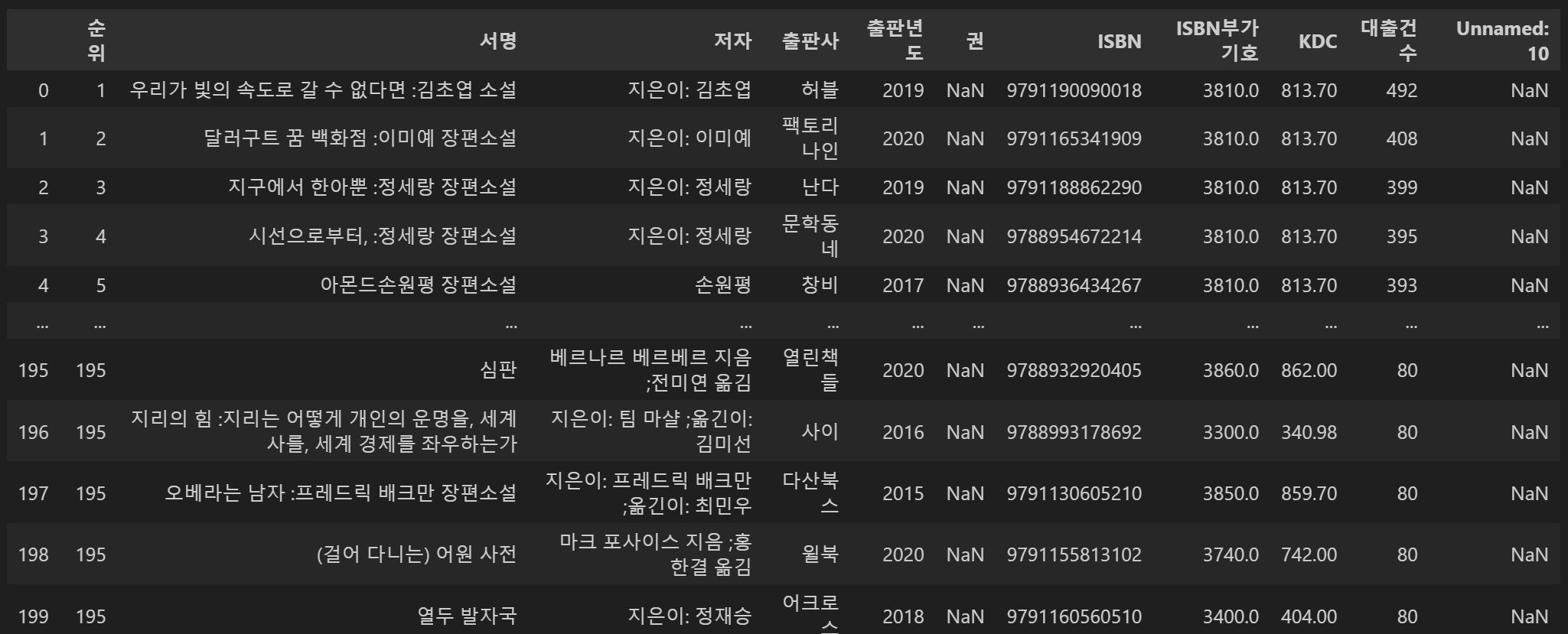
Pandas.iloc() 함수의 경우 인덱스의 위치를 이용하여 슬라이싱을 할 수 있는 함수이다. 따라서 행 전체와 열을 마지막을 제외하고 슬라이싱을 하면 이를 지울 수 있다. 이를 통하여 인기도서의 정보를 얻을 수 있다.
df = df.iloc[:, :-1]
df
5. Web scraping
Web scraping은 web에 있는 데이터를 추출하는 과정을 말한다. 목표는 20대 인기 도서들의 쪽수를 구하는 것이다. 이 중 api를 통하여(정확히는 나는 api로 구하지는 않았지만) 인기 도서 정보를 구했다면, Web scraping을 통하여 yes24가 책의 판매 페이지에서 책의 정보를 제공한다는 점을 이용하여 yes24에 있는 해당 도서의 쪽수 정보를 받아오는 것이다.
yes24의 경우 도서 이름뿐만 아니라 ISBN을 사용해서 검색해도 도서를 찾을 수 있다.
예스24
YOUR EVERY STORY 문화 콘텐츠 플랫폼, 예스24
www.yes24.com
직접 책을 검색해 보면, 검색 결과 주소가 "주소+'query=ISBN' "으로 되어 있는 것을 알 수 있다.
9791190090018 - 예스24
www.yes24.com
따라서 책의 쪽수데이터가 있는 판매 페이지를 가기 위해, yes24에서 ISBN으로 검색하는 것까지 requset.get()으로 구현할 수 있다.
import requests
isbn = '9791190090018'
url = 'https://www.yes24.com/Product/Search?domain=ALL&query={}'
r = requests.get(url.format(isbn))
r.text
결과 값은 검색한 페이지(책의 검색결과 목록)의 html문서이다. 이를 통해 판매 페이지로 가야 한다. 이를 알 수 있는 방법은 웹사이트가 어떤 방식으로 링크되어 있는지 확인하는 것이다. 웹사이트에서 F12를 눌러 개발자 도구를 들어가면 마우스가 올라간 html블록이 어떤 코드로 되어 있는지를 알 수 있다.

다른 책을 검색해서 보면, 다른 책들도 비슷한 형식으로 되어 있는데, <a> tag에 class 이름은 'gd_name'그리고 각 책에 알맞은 href가 속성으로 지정되어 있는 것을 알 수 있다. yes24 웹사이트의 경우 해당 <a> tag를 클릭 시 " 'https://www.yes24.com' + 'href' "로 연결되는 것을 알 수 있다.
그러면 해당 부분을 requests.get()으로 받아온 response에서 찾으면 다시 책의 판매 페이지로 갈 수 있다. 받은 데이터가 html(현재는 str)인데 이를 html로 다룰 수 있는 라이브러리로 bs4의 BeautifulSoup가 있다. BeautifulSoup() 함수를 이용하여 파서를 선택해 html을 다룰 수 있다. 'html.parser'는 파이썬 자체에 내장되어 있는 html을 다루는 라이브러리이다.
from bs4 import BeautifulSoup
# 파서>> 입력 데이터를 받아 데이터 구조를 만드는 소프트웨어 라이브러리
soup = BeautifulSoup(r.text, 'html.parser')
soup
BeautifulSoup로 다루면 다양한 함수를 사용할 수 있는데, XML를 다뤘던 것처럼 find() 함수를 사용할 수 있다. find() 함수는 tag와 attrs(attribute)를 받아 해당 엘리먼트에 접근할 수 있다.
prd_link = soup.find('a', attrs={'class':'gd_name'})
prd_link
해당요소의 attribute는 다음과 같이 구할 수 있다.

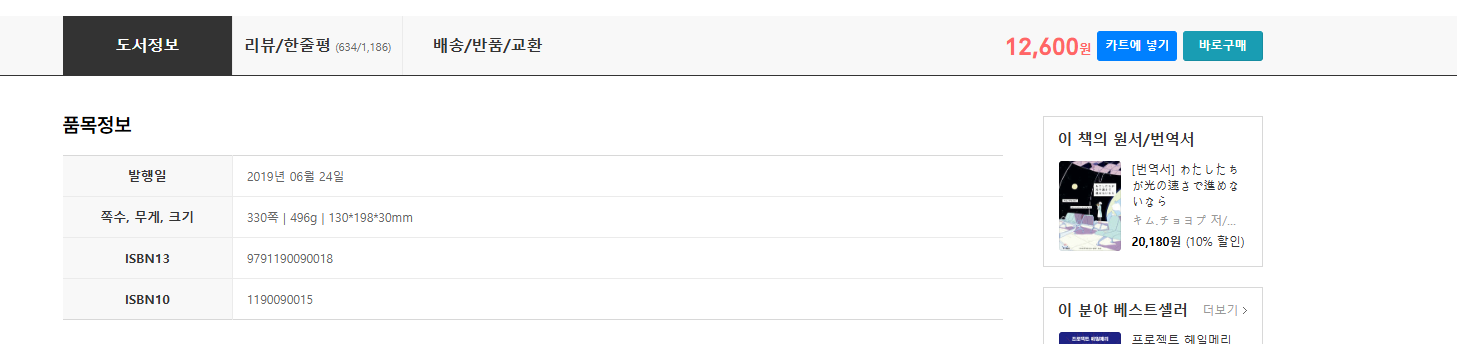
지금까지 했던 방식으로 판매 페이지의 품목정보에서 책의 쪽수 정보를 받아오면 결과적으로 인기 책의 쪽수들을 알 수 있다.
6. 20대 인기 책의 쪽수 정보 구하기
결론적으로 다음은 내가 작성한 미리 준비된 20대 인기 책들에 관한 json파일로부터 web scraping을 통하여 책의 쪽수를 구하는 파이썬 코드이다.
import sys, os
# 현재 파일의 부모 디렉터리를 sys.path에 추가하여 상위 폴더의 파일들을 가져올 수 있도록 설정
sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__))))
import pandas as pd
from bs4 import BeautifulSoup
import requests
def get_page_cnt(isbn):
# isbn으로 검색
url = 'https://www.yes24.com/Product/Search?domain=ALL&query={}'
response_isbn_web = requests.get(url.format(isbn))
# 도서 상세페이지 구하기
soup_isbn_web = BeautifulSoup(response_isbn_web.text, 'html.parser')
book_juso_info = soup_isbn_web.find('a', attrs={'class':'gd_name'})
if book_juso_info == None:
print('검색 실패. 책을 발견하지 못함')
return
# 도서 상세페이지 접속 (나미 어쩌구는 전체 url이 들어가 있음)
if book_juso_info['href'].startswith("https://"):
url2 = book_juso_info['href']
else:
url2 = 'https://www.yes24.com'+book_juso_info['href']
response_book_web = requests.get(url2)
soup_book_web = BeautifulSoup(response_book_web.text, 'html.parser')
book_info = soup_book_web.find('div', attrs={'id':'infoset_specific'})
# 책의 쪽수, 무게, 크기를 추출 (나미야 잡화점의 기적은 절판된거 같다. 중고밖에 없음)
try:
book_tr_list = book_info.find_all('tr')
except:
# 책이 판매하고 있지 않음
print(book_juso_info.text, '는 현재 판매를 하지 않는 것 으로 추정')
return None
for tr in book_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
page_td = tr.find('td').get_text()
return page_td.split()[0]
print("책의 정보를 발견 못함")
return
def get_page_from_df(df):
df = df['ISBN']
return get_page_cnt(df)
if __name__=='__main__':
df = pd.read_json('data\\20s_best_book.json')
books = df[['순위', '서명', '저자','출판사', '출판년도','ISBN']]
books = books.head(10)
page_cnts = books.apply(get_page_from_df, axis=1)
print(page_cnts)
이게 책에 나온 코드와 조금 다른데, 이를 설명하겠다.
일단 책에 나온 코드를 진행하다 보면, 다음과 같은 에러가 발생한다. 잘 모르겠지만 web scraping 중 나온 에러인 것을 알 수 있다.

따라서 디버깅을 진행하다 보면 특정 ISBN에서 계속 안되고 있는 것을 알 수 있다.

isbn변수를 통해 책을 보면 나미야 잡화점의 기적이란 책인 것을 알 수 있다. 해당 웹사이트에 가서 확인해도 되고, isbn변수 위에 book_juso_info변수를 봐도 확인할 수 있는데, href가 조금 다르다는 것을 알 수 있다. 조금 헷갈릴 수 있지만 우리는 https://www.yes24.com가 없다고 가정하고 코드를 작성했는데, href에 이미 들어가 있는 것을 알 수 있다. 따라서 우리는 'https://www.yes24.comhttps://www.yes24.com/...'이런 식으로 접속을 하고 있어서 생긴 문제였던 것이다. 따라서 이를 동적으로 맞춰서 접속하도록 바꾸었다.
# 도서 상세페이지 접속 (나미 어쩌구는 전체 url이 들어가 있음)
if book_juso_info['href'].startswith("https://"):
url2 = book_juso_info['href']
else:
url2 = 'https://www.yes24.com'+book_juso_info['href']
이를 해결해도 문제가 해결이 되지 않는데, 이는 직접 사이트를 들어가 보면 알 수 있다. yes24에 ISBN 9788972756194를 검색해 보면 나미야 잡화점의 기적이 나오는데, 2025-01-13 기준으로 책이 판매가 되지 않고, 중고 서적으로만 거래가 되고 있다는 것을 알 수 있고, 해당 판매 페이지는 품목 정보들을 제공을 하고 있지 않는다는 것을 알 수 있다. 근데 사이트를 더 살펴보니 yes24에서 판매 중인 책은 품목 정보를 제공하는데 중고 판매는 이를 제공하지 않는 것으로 파악했다. 따라서 코드를 품복 정보가 없다면 책이 판매가 끝났다고 판단하고, 다음과 같이 고쳐서 판매가 끝난 책은 정보를 None으로 넘겼다.
# 책의 쪽수, 무게, 크기를 추출 (나미야 잡화점의 기적은 절판된거 같다. 중고밖에 없음)
try:
book_tr_list = book_info.find_all('tr')
except:
# 책이 판매하고 있지 않음
print(book_juso_info.text, '는 현재 판매를 하지 않는 것 으로 추정')
return None
이 2가지를 해결하면 코드가 정상 작동한다.

혹시 책과 다른 데이터를 쓴 것은 아닌가 생각이 들어서 확인했더니 다음과 같다. 140~141p에 merge() 함수 부분을 보면, 값이 다른 것을 알 수 있다.


먼가 이상해서 그 아래를 보니 원본데이터에서 1등과 10등의 책이름이 같고, yes24의 책 정보를 직접 확인해 보니, 나의 결과 값이 맞는 것 같다.
7. 숙제

Study_with_book/hongong_data_with_python at main · dy0221/Study_with_book
Contribute to dy0221/Study_with_book development by creating an account on GitHub.
github.com
'혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공 분석] 다양한 그래프 그리기 (0) | 2025.02.23 |
|---|---|
| [혼공 분석] 선, 바 그래프 그리기 (0) | 2025.02.16 |
| [혼공 분석] 데이터 분석 (3) | 2025.02.03 |
| [혼공 분석] Data cleaning (0) | 2025.01.22 |
| [혼공 분석] 혼자 공부하는 데이터 분석 with 파이썬 (0) | 2025.01.05 |



