
혼공 학습단 13기에 혼자 공부하는 데이터 분석 with 파이썬책으로 신청하였다. 공부를 하는데 기한이 정해져 있으면 동기부여로 인해 끝까지 완료하기 더 쉽다고 생각했고, 데이터 분석이나 시각화를 필요할 때마다 찾아서 하다가, 한번 책을 읽어볼까 고민하던 중에 한번 찍먹 해보자는 생각으로 신청하게 되었다.
혼공 학습단은 한주마다 챕터 하나씩 공부하고 정리하는 형식으로 진행된다.

1. 공부 환경
책에서는 colab에서 사용하는 것을 전제로 진행된다. 하지만 나는 vscode에서 하려고 한다. window에서 아나콘다를 이용하여 개발환경을 만들었다.

책을 읽으면서 해본 코드 정리 같은 경우는 각 챕터마다 폴더로 정리하고, data들도 따로 모아서 정리하려고 한다.
Study_with_book/hongong_data_with_python at main · dy0221/Study_with_book
Contribute to dy0221/Study_with_book development by creating an account on GitHub.
github.com
vscode에서 데이터를 조금 더 편하게 볼 수 있는 익스텐션은 Data Wrangler가 있다.

사용방법은 break point를 만들어서 디버그 모드를 들어가서 보면 data frame변수를 우클릭할 시 Data Viewer로 볼 수 있다. 이를 클릭 시 Data Wrangler를 이용하여 data frame을 편하게 볼 수 있다.
vscode에서 주피터 노트북을 디버깅할 경우 똑같이 break point를 설정하고 진행하면 된다. 하지만 주피터 노트북은 내가 사용해 보니 각 셀 단위로 debug이 진행되는 것으로 파악했다. 디버깅 실행하는 방법은 셀의 왼쪽의 실행버튼의 확장버튼을 눌러 실행할 수 있다.

2. CSV파일 읽기
csv(comma-separated-values) 같은 경우 이름 그대로 콤마(,)를 이용하여 데이터를 구분한 데이터 분류 방식이다. csv는 각 행과 열을 각각 레코드(record)와 필드(field)로 구성이 된다.
각 데이터는 콤마로 분리되어 있다. 레코드들은 줄로, 필드들은 ""로 구분 되어 있다.

csv를 파이썬 파일로 불러오기 전에 csv파일을 컴퓨터에 다운을 받아야 한다. 구글드라이브에 올라가 있는 파일을 다운받는 방법 중 하나는 파이썬에서 gdown 라이브러리를 이용하는 것이다. 이를 이용하여 남산도서관 장서 대출목록을 다운 받았다.
"""
$ pip install gdown
"""
import sys, os
# 현재 파일의 부모 디렉터리를 sys.path에 추가하여 상위 폴더의 파일들을 가져올 수 있도록 설정
sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__))))
import gdown
gdown.download('https://bit.ly/3eecMKZ',
'data\\남산도서관 장서 대출목록 (2021년 04월).csv', quiet=False)
이때 나의 경우는 파일 관리를 위하여 data를 사용한 코드의 위치에서 밖으로 뺐다. 파이썬 같은 경우 같은 층(폴더의 층)을 경로로 사용하려면 절대 경로를 대부분의 경우 이용해야 한다. 하지만 절대경로를 사용하는 것은 관리하기 번거롭고 확장성이 부족하다. 따라서 workspace의 위치를 sys.path에 추가해서 상대 경로를 사용하도록 설정했다.
남산도서관 장서 대출 목록의 경우 EUC-KR로 인코딩이 되어 있다. 이를 확인하기 위해서는 chardet 라이브러리에서 chardet.detect() 함수를 사용해야 한다. chardet.detect() 같은 경우는 text 데이터가 아닌 binary 데이터가 필요하다. 따라서 open 함수에서 rb모드(바이너리 읽기 모드)를 사용해야 한다.
"""
pip install chardet
"""
import chardet
with open('..\\data\\남산도서관 장서 대출목록 (2021년 04월).csv', mode='rb') as f:
data = f.readline()
print(chardet.detect(data))

3. Pandas 사용하기
판다스는 파이썬에서 데이터 분석을 도와주는 라이브러리이다. 판다스는 대표적으로 DataFrame을 사용해서 데이터를 관리한다. 데이터 프레임의 경우는 다음과 같은 매개변수를 갖는다.
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=None)
csv파일을 데이터 프레임으로 불러오려면, read_csv() 함수를 사용해야 한다.

근데 이를 사용하면 경고가 나타나게 된다. 이는 data frame의 경우 데이터를 읽을 때, 각 열의 데이터 타입은 단일 타입을 허용한다. 하지만 이를 지정하지 않을 시 데이터를 읽으면서 자동으로 데이터 타입을 읽게 된다. 이때, 데이터가 중간에 바뀔 경우 이런 식으로 경고를 하게 된다. 이를 해결하기 위해서는 위에 있는 파라미터 중 dtype을 명시적으로 알려주거나, law_memory = False로 설정해 이를 막을 수 있다.
# dtype을 명시적으로 설정하여 경고 방지
df = pd.read_csv('../data/남산도서관 장서 대출목록 (2021년 04월).csv',
encoding='EUC-KR',
dtype={'ISBN': str, '세트 ISBN': str, '주제분류번호': str})
DataFrame.head(), DataFrame.tail() 함수의 경우 각각 데이터프레임의 처음 5개, 마지막 5개를 출력한다.

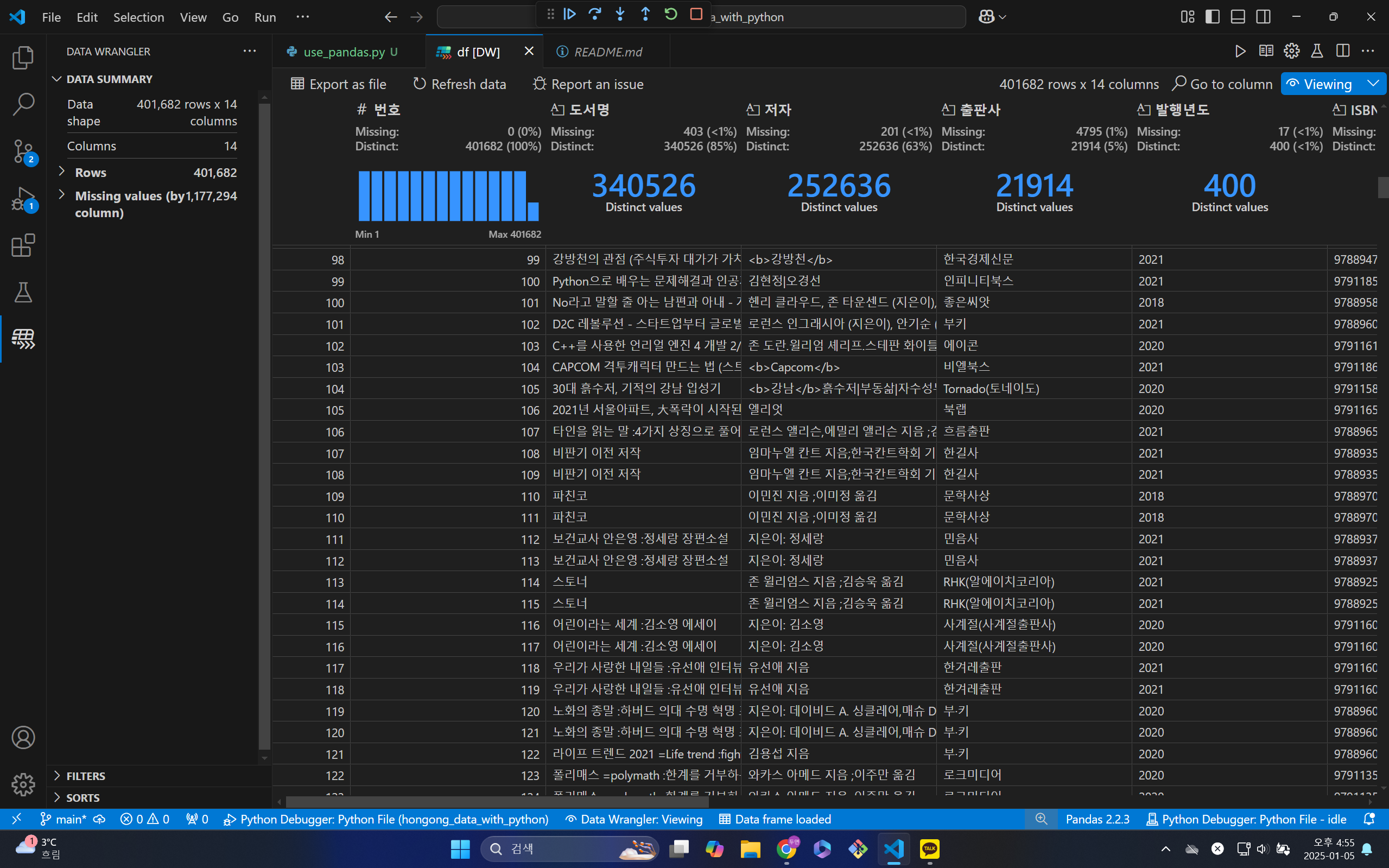
사진을 보면 dtype을 설정해 준 값들을 보면 NaN값이 껴있는 것을 알 수 있다. 이를 확인하기 위해 type을 확인해 보면 다음과 같다.
# 특정 셀의 데이터 타입 확인
type_data = df['세트 ISBN'].iloc[109]
type2_data = df['세트 ISBN'].iloc[105]
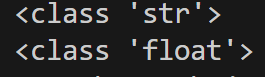
print(type(type_data)) # <class 'str'> for data
print(type(type2_data)) # <class 'float'> for NaN
NaN값의 경우는 데이터프레임이 float로 설정하지만, 정상적인 값의 경우는 str로 설정된다는 것을 알 수 있다. 따라서 이번 경우는 데이터가 없는 경우로 인해 이렇게 된 것을 알 수 있다.
만약 csv파일 안에 이미 인덱스가 들어가 있는 경우, index_col = 0를 설정함으로써 인덱스를 저장하지 않을 수 있다. 만약 이미 있는데 이를 설정하지 않을 경우 데이터프레임에서 또 인덱스를 추가한다.
namsan_df = pd.read_csv('..\\data\\namsan_04_2021.csv', index_col=0,
dtype={'ISBN': str, '세트 ISBN': str, '주제분류번호': str})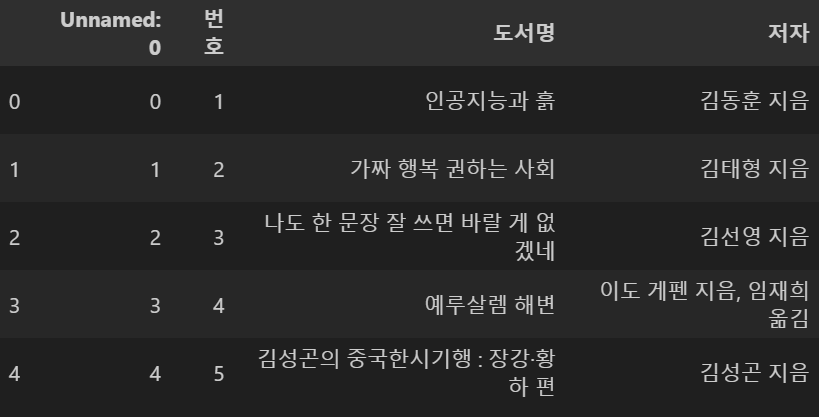

반대로 데이터 프레임을 csv파일로 저장하려면, to_csv() 함수를 사용해야 한다. 이때, 인덱스를 빼고 저장하려면 index=False로 설정하여 인덱스를 빼고 저장할 수 있다.
df.to_csv('..\\data\\namsan_04_2021.csv', index=False)
4. 숙제

'혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공 분석] 다양한 그래프 그리기 (0) | 2025.02.23 |
|---|---|
| [혼공 분석] 선, 바 그래프 그리기 (0) | 2025.02.16 |
| [혼공 분석] 데이터 분석 (0) | 2025.02.03 |
| [혼공 분석] Data cleaning (0) | 2025.01.22 |
| [혼공 분석] API, web scraping (1) | 2025.01.14 |



