1. 데이터 분석
데이터를 분석할 때 해야 할 것이 매우 많은데, 판다스는 이런 데이터 분석에서 기초적인 부분을 많이 함수로 제공한다.
DataFrame.describe() 함수는 수치형 데이터나 범주형 데이터를 다룰 때, 해당 데이터에 대한 요약 통계를 제공한다.

count : 결측 값을 제외한 데이터 개수
mean : 평균
std : 표준편차
min, max : 최솟값, 최댓값
25%, 50%, 75% : 분위 수
각각에 대한 정보를 따로 구하는 함수 또한 제공한다.
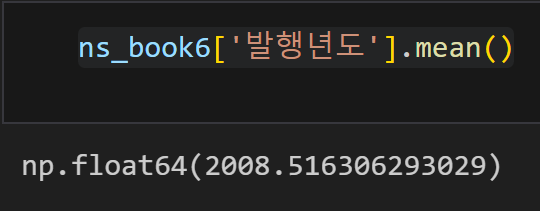
DataFrame.mean() : 평균을 구하는 함수
DataFrame.median() : 중앙 값을 구하는 함수

DataFrame.min() or max() : 최대 최소를 구 하는 함수

DataFrame.quantile() : 분위 수를 구하는 함수, 인자로 원하는 위치를 넣어 구할 수 있다.

DataFrame.var() : 분산을 구하는 함수
DataFrame.std() : 표준편차를 구하는 함수

각 값들이 describe()함수를 썼을 때 나온 값과 같은 것을 알 수 있다.
데이터중 어떤 값이 가장 많이 나왔는 지 알기 위해서는 DataFrame.mode() 함수를 사용 하면 된다. 실제로 맞는지 확인해 보면, 다음과 같다.


2. 데이터 분포 시각화(산점도, 히스토그램, 상자 수염)
데이터 분포를 그래프로 그리는 방식에는 산점도, 히스토그램, 상자 수염이 있다.
산점도는 변수 2개를 좌표로 그래프에 나타내는 방식을 말한다. plt.scatter() 함수를 이용해 그릴수 있다. alpha 매개 변수를 이용해 좌표에 불투명도를 추가할 수 있다. 이를 통해 많이 겹쳐있으면 진하게 나타나 데이터의 분포를 쉽게 알 수 있다.
ns_book7['도서권수'], ns_book7['대출건수'], alpha=0.1) # 0~1 1로 갈수록 짙게 불투명함.>>겹치면 짙게 나타남

히스토그램은 우리가 아는 막대그래프로, 일정 구간(bin)으로 나누어 데이터의 분포를 표현하는 방식이다. plt.hist() 함수를 이용해 만들 수 있고, plt.yscale(), plt.xscale()함수를 이용해 그래프 축의 스케일을 지정할 수 있다.
plt.hist(ns_book7['대출건수'], bins=100)
plt.yscale('log')
plt.show()
마지막으로 상자 수염은 한국 주식에서 많이 사용하는 캔들차트와 매우 비슷하다. (캔들차트의 원형) 네모를 통해, 25%, 50%,75% 사분위 수를 표현하고, 네모에 꼬리를 만들어 최솟값과 최댓값을 표현한다. plt.boxplot() 함수를 이용해 만들 수 있다.
plt.boxplot(ns_book7[['대출건수','도서권수']])
plt.yscale('log')
plt.show()
3. 숙제

'혼자 공부하는 데이터 분석 with 파이썬' 카테고리의 다른 글
| [혼공 분석] 다양한 그래프 그리기 (0) | 2025.02.23 |
|---|---|
| [혼공 분석] 선, 바 그래프 그리기 (0) | 2025.02.16 |
| [혼공 분석] Data cleaning (0) | 2025.01.22 |
| [혼공 분석] API, web scraping (1) | 2025.01.14 |
| [혼공 분석] 혼자 공부하는 데이터 분석 with 파이썬 (0) | 2025.01.05 |



