공부를 하는 입장이기 때문에, 내용에 오류가 있을 수 있습니다. 오류가 있다면 적극적으로 알려주시면 감사합니다!
1. Two_Layer_Network
각 계층에 대하여 알았으므로, 이를 활용하여 전에 있던 2층 신경망의 업그레이드 버전의 예시이다. Backpropagation.two_layer_net.py에서 확인할 수 있다.
import sys, os
# 내경로가 현재 폴더가 아닌 상위 폴더로 바꿈 # 부모 디렉터리의 파일을 가져올 수 있도록 설정
sys.path.append(os.path.dirname(os.path.abspath(os.path.dirname(__file__))))
import numpy as np
from collections import OrderedDict #상위 파이썬은 필요없으나, 하위의 호환성 보장
from Backpropagation.affine_layer import Affine
from Backpropagation.relu_layer import Relu
from Backpropagation.softmax_with_loss_layer import SoftmaxWithLoss
from Neueral_network_learning.numetical_gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
if t.ndim != 1 : t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x : 입력 데이터, t : 정답 레이블
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
def gradient(self, x, t):
# forward
self.loss(x,t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse() #역전파니깐 뒤에서 부터
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads
계층을 순회하면서 순전파를 계산하기 위하여 배열의 순서가 중요하다. 파이썬의 최신버전은 딕셔너리가 차례대로 정리되지만, 낮은 버전은 그렇지 않다. 따라서 호환성을 위하여 OrderedDict를 사용한다.
self.layers = OrderedDict()
self.layers['Affine1'] = Affine(self.params['W1'], self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'], self.params['b2'])
self.last_layer = SoftmaxWithLoss()
기울기를 구하는 방법은 매우 간단하다. 순전파를 통하여 오차를 구하고, 역전파를 통하여 각각의 어파인 계층에서 매개변수의 기울기를 받아오면 된다.
def gradient(self, x, t):
# forward
self.loss(x,t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse() #역전파니깐 뒤에서 부터
for layer in layers:
dout = layer.backward(dout)
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads
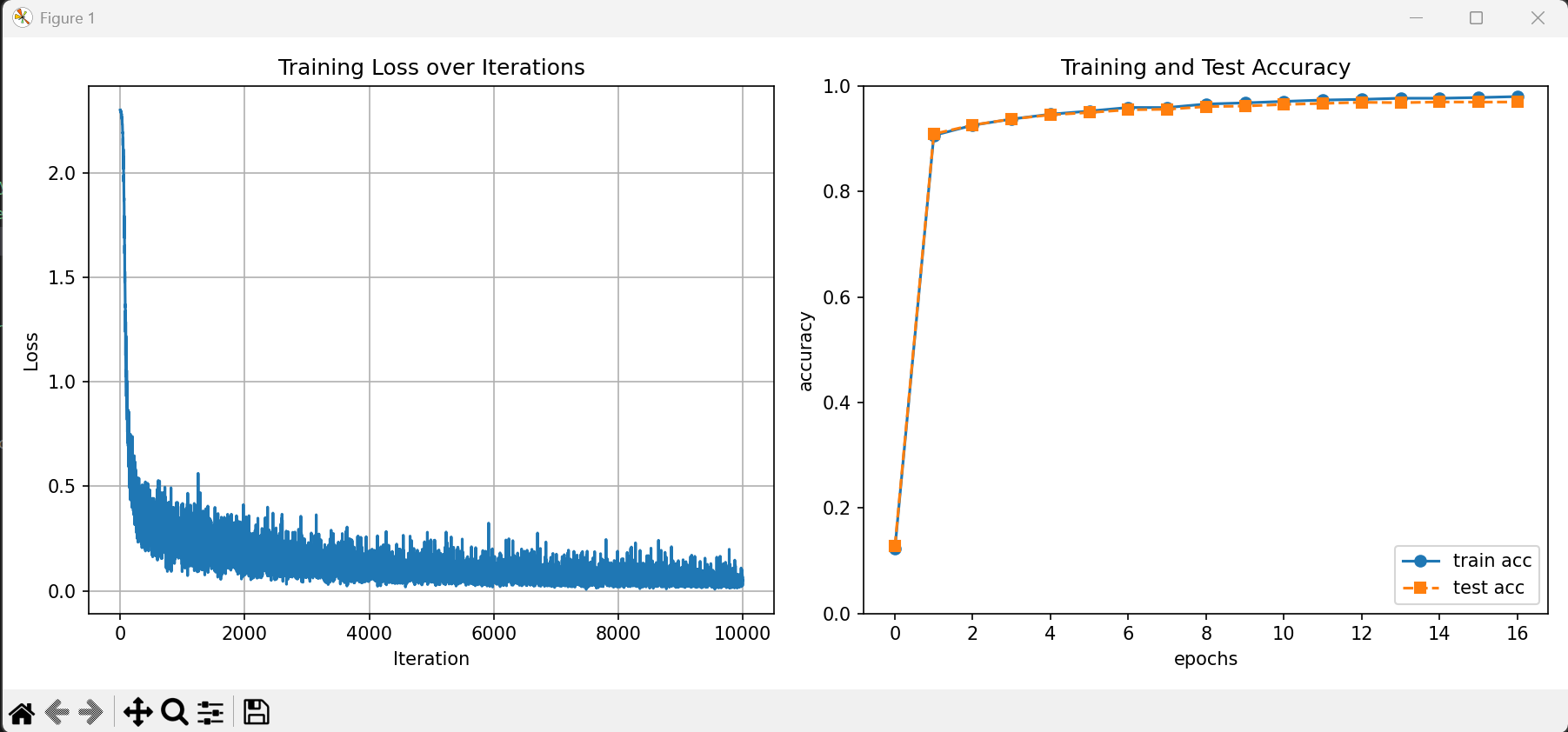
실제의 결과를 확인해보면, train data와 test data에 잘 학습이 된 것을 확인할 수 있다.
'밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| Learning Skill (0) | 2025.01.03 |
|---|---|
| [논문 리뷰]An overview of gradient descent optimization algorithms*SebastianRuder (0) | 2024.12.31 |
| Backpropagation (0) | 2024.12.24 |
| Neural Network Learning Example (2) | 2024.12.22 |
| Neural Network Learning (1) | 2024.12.22 |



